

What is a scientific field?
Ask a librarian. Ask a computer scientist. Ask an economist.

A few months ago, I integrated dimensions.ai citations on my personal publications website. It includes not only the total citations, but also the field citation ratio and the relative citation ratio.
For example, for the first SemiBin paper, this is what it shows:

I confess that I had seen these numbers, but was not 100% sure what they meant. Given that I was now displaying them on my website, I felt I should know more.
They are both the same concept, solving the same problem. The issue is that the raw number of citations is not very meaningful. Is 94 citations good? It will first of all depend on how long the paper has been out (as all papers get more citations with time). But we also know that some fields cite more than others. Oncology cites a lot, bioinformatics not that much.1 Therefore, the median paper in oncology will get more citations than the median paper in bioinformatics.
Therefore, we should normalize the number of citations by comparing to the expected number of citations given (i) the time of publication, and (ii) the field:
This is the concept behind both the field and the relative citation ratios. They just differ in how they compute the expected citations. They both attempt to find a set of “comparable articles” and use its average citations as the background.
What are the right set of articles to compare to? Depends who you ask.
Asking a librarian leads to the field citation ratio. From this more traditionalist point of view, a field is an FoR (Fields of Research) code. The SemiBin paper got assigned 3102 (Bioinformatics and Computational Biology), 3107 (Microbiology), and 46 (Information and Computing Sciences), so we can check other papers with the same codes and year of publication and get the expected value.2
Asking a computer scientist leads to the relative citation ratio. Instead of assigning each document a set of predefined codes, which could fail in corner cases and does poorly with transdisciplinary work, we could instead use the citation graph itself to define the field.
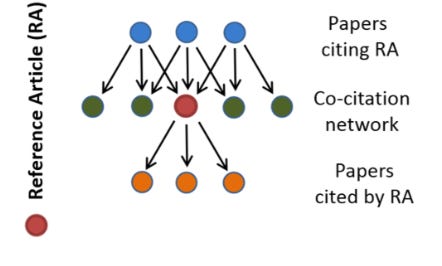
As shown in Fig 1A above, the field of a paper (in red) are the papers that are cited at the same time as it is (the co-citation network, in green). Instead of the actual citations of the papers in the co-citation network, the journal citation rate of the journals where those papers were published is used (this is intended to smooth out effects of outlier papers).3 So, if a paper is get co-cited with papers in Nature (impact factor=50), that counts for less than if it getting co-cited with papers in some MDPI rag (impact factor=1.7).
What would an economist say? The economist answer is that we should choose a metric which leads to good incentives. These metrics are still too niche to have been subject to Goodhart’s Law. Few people are trying to game them (unlike the widely used journal impact factor), but we can ask how one could improve the ratios for a paper. Obviously, the best is to get more citations, but those are pretty good incentives, it’s good to sell your papers at conferences/social media/newsletters/… However, how would we game the score to get a lower expected number of citations (thus increasing our ratios)?
For example, to get a higher field relative ratio, I would like my paper to be classified in a field with a lower average citation rate. Not sure how I would go about doing this, but if the journal is used to determine the FoR code, this may lead to perverse results. In a related context, have heard of of folks who are evaluated based on whether they publish in the top journals for the respective field. So they prefer to submit to very specialised journals instead of those that cater to a broader readership. Nature Communications, the journal that published SemiBin1 and is an excellent journal would be right out as it is not a top journal in the field of “multidisciplinary.” These seem like bad incentives.
When it comes to the relative citation ratio, it actually seems a very robust metric because I can only partly control the co-citation network. However, there is at least one element of the co-citation network that I do control, namely when I am self-citing.4 Thus, perhaps the best is to include a few citations to JIF=0.1 journals to lower the expected number for my own papers. Still, the impact of these gimmicks would likely be limited at best.
All in all, despite it feeling counter-intuitive that it is better if my papers get cited alongside MDPI slop instead of other high-profile papers, I cannot really see this as a fatal flaw in the metric and I like the relative citation ratio (currently 6.22 for the SemiBin1 paper5).
This is actually a bit of a pet peeve of mine, how bioinformaticians generally don’t cite relevant work and this leads to overall lower citation rates for the field.
The details of how multiple codes are handled are not 100% clear to me. The dimensions.ai docs are not consistent. Sometimes, they seem to assume that a single code is used, and I guess it would mean the first one. Other times, it seems that only papers with the exact same set of codes are considered. These difficulties are one of the downsides of FoR codes.
Technically there is a normalization per year as well, in both the numerator (citations per year) and denominator (expected citations per year), but these roughly cancel each other out. They don’t exactly cancel each other out because the year of publication is taken out of the equation given the following observations: “The publication year is nearly always partial, and because articles receive a low number of citations in the calendar year of their publication compared to subsequent years. In practice, the sum of the citations in years 0 and 1 (the year of publication and the following year) is close to the mean number of citations per year in the following 8 years.”
Some people seem to treat any self-citation as morally suspicious, but some self-citation is to be expected in the healthiest of scientific environments as current work builds on past work.
The second digit after the decimal point is probably nonsensical, though. A little back-of-the-envelope math tells me that it would be 6.15 with one fewer citation and 6.28 with one more, so it is probably a lot more meaningful to say the RCR is 6.2 or even 6¼, using increments of ¼.